CernDOC, a fertile ground for the web's inception.
Authors/Creators
Description
It is widely acknowledged that the World Wide Web took its first steps towards success at CERN. However, lesser well known is that earlier in the 80s, CERN teams had already developed CERNDOC, a very advanced documentation system, and one of the first to implement the client-server model. This same idea was later used in the development of the Web.
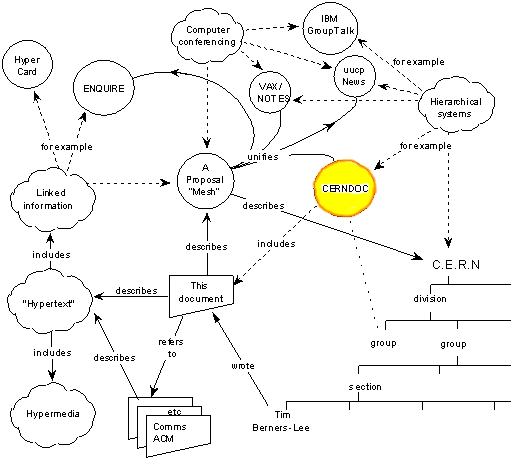
The scheme used by Tim Berners-Lee to present the web. In yellow, the CERNDOC box.
CERNDOC was a very powerful system for retrieving information but there were factors that impeded upon its ease of use: “Documents could only be retrieved by sending a request to the server and it did not include a browser interface”, says Eric. “CERNDOC was supported by a language that did not make use of hyperlinks, rendering it impossible to link documents together. One had to select documents from the database in order to view them ”.
"When we started to implement the system, we decided to use the Standard Generalized Markup Language (SGML)" explains Eric. "At the time, it was the language we were instructing people to use on our mainframes. It was a meta language that IBM had standardized for text processing. It did not directly contain processing instructions and it had to be translated to represent the text processing commands that it contained. CERNDOC pioneered the idea of storing documents using an application independent interchange format allowing them to be displayed on different client platforms.”
As a result of the complexity of the SGML language, it was not used for the Web. Rather, Tim Berners-Lee used features from a number of SGML implementations to create a more simplified language, the HTML, which included an anchor for hypertext links and did not depend on a Document Type Definition (see box).
As the Web started to gain a good reputation within the physics community, CERNDOC and SGML were faced with a big problem – the dawn of the PC era. "All of a sudden, PCs became much more popular than IBM VM/CMS," describes Eric. "Slowly, we moved first to Suns, then to PCs and Macintoshes. The world went “What You See is What You Get” thanks to Microsoft Word and Adobe PDF became the de facto document interchange format. You could say CERNDOC and SGML died at the same time."
Although CERNDOC did not meet a very successful fate, it contained ideas that proved to be an important stepping-stone in the path to the development of the WEB.
| Document Type Definition A Document Type Definition or a DTD is a required component when using an SGML-type meta language. It is a set of markup declarations that define a document type and provides instruction for which elements will appear in a document and where. XML is a simplified version of SGML. |
Other (French)
Chacun sait que c’est au CERN que le « World Wide Web » a fait ses premiers pas avant de connaître son succès actuel. Ce qu’on sait moins, en revanche, c’est que, dès les années 1980, des équipes du CERN avaient développé un système de documentation très avancé, appelé CernDOC, qui était notamment l’un des premiers à utiliser le modèle client-serveur, repris plus tard lors du développement du web.
Le schéma utilisé par Tim Berners-Lee pour présenter le WEB. En jaune, le cercle de CERNDOC.
CernDOC était très performant quand il s’agissait de retrouver des informations, mais certains facteurs nuisaient à sa facilité d’utilisation : « Le seul moyen de récupérer un document était d'envoyer une requête au serveur ; or celui-ci ne possédait pas d’interface de navigation, continue Eric. De plus, CernDOC fonctionnait selon un langage qui n’utilisait pas de liens hypertexte, ce qui fait qu’il n’était pas possible de lier des documents. Pour pouvoir visualiser un document, on était obligé de le sélectionner à partir de la base de données ».
« Quand nous avons commencé à implémenter le système, nous avons décidé d’utiliser le langage SGML, explique Eric, et nous demandions aux gens de l'utiliser sur nos ordinateurs centraux. Il s’agit d’un métalangage qu’IBM avait normalisé pour le traitement de texte. Il ne comportait pas de réelles instructions de traitement : il fallait donc le traduire pour représenter les commandes de traitement de texte qu’il contenait. CernDOC a été le premier système à stocker des documents à l'aide d'un format d'échange indépendant de l'application, ce qui permettait de les afficher sur différentes plateformes de clients. »
En raison de sa complexité, ce n’est pas le langage SGML qui a été utilisé pour le web, Tim Berners-Lee ayant préféré reprendre des caractéristiques provenant d’un certain nombre d’applications SGML pour créer un langage simplifié, le langage HTML, qui comprenait une ancre pour liens hypertexte et ne dépendait pas d’une Définition de type de document (voir encadré).
Alors que le milieu des physiciens commençait à reconnaître l’intérêt que le web pouvait représenter, CernDOC et le langage SGML ont été confrontés à un sérieux problème : l’avènement de l’ère du PC. « Les VM/CMS d’IBM ont été brusquement supplantés par les PC, rappelle Eric. Nous sommes passés peu à peu des VM aux Sun, puis aux PC et aux Mac. Grâce à Microsoft Word, le monde entier s’est converti au WYSIWYG (tel écran - tel écrit) et Adobe PDF est devenu de facto le format standard d’échange de documents. En un sens, c'est ce qui a signé l'arrêt de mort du SGML – et de CernDOC. »
CernDOC a fini par être abandonné ; pourtant, les idées qui ont présidé à sa conception auront marqué une étape importante dans le développement du Web.
| Définition de type de document Une Définition de type de document ou DTD est l’une des composantes d’un métalangage de type SGML. Il s’agit d’une série de déclarations de balisage définissant un type de document et contenant les instructions qui déterminent la nature et l'emplacement des éléments qui apparaîtront sur un document. XML est une version simplifiée de SGML. |
Files
CERNDoc_image.jpg
Files
(107.4 kB)
| Name | Size | Download all |
|---|---|---|
|
md5:e5fbf21c169cebdcf356df5a257cb70d
|
107.4 kB | Preview Download |
{kind=link}
Additional details
Identifiers
- CDS
- 1271708
- CDS Report Number
- BUL-NA-2010-156
Related works
- Is published in
- Periodical issue: 0s4qq-7gz77 (CDS)
- Periodical issue: 2fkzf-pd441 (CDS)